我家裡有一張 NVIDIA GeForce RTX 2070 顯卡,每次在 Hugging Face 看到一些不錯的 AI 模型想在本機跑起來,無奈 GRAM 只有 8GB 而已,連個 7B 的 LLM 模型都跑不起來。上個月我在上海參加 2023 Google I/O Connect 大會,認識了一位 GDE 在 Lepton AI 工作,他們公司主要做 LLMOps 工具,可以無腦的將許多開源的 LLM 模型部署起來,而且還有免費的 GPU 資源可以使用,這樣就可以讓我們這些沒有太多 GPU 資源的開發者也可以輕鬆的玩 LLM 了。這篇文章我打算來介紹一下如何使用 Lepton AI 的工具在本機與雲端部署台灣最近釋出的 Taiwan-LLM-7B 模型。

在本機跑 LLM 模型
Lepton AI 近期開源了他們的 LLMOps 工具,如果你想要利用他們的 leptonai 工具將 LLM 模型部署在本機,是完全免費的!
GitHub: https://github.com/leptonai/leptonai
以下是利用 Lepton AI 在 Windows 10 部署 gpt2 模型的步驟:
-
在 Windows 必須先啟用作業系統的長檔名支援
請以系統管理員身分啟動 PowerShell 並執行以下命令:
New-ItemProperty -Path "HKLM:\SYSTEM\CurrentControlSet\Control\FileSystem" -Name "LongPathsEnabled" -Value 1 -PropertyType DWORD -Force
Enable Long Paths in Windows 10, Version 1607, and Later
如果沒有啟用這個機碼值,會在下個步驟安裝時遇到以下錯誤訊息:
ERROR: Could not install packages due to an OSError: [Errno 2] No such file or directory: 'C:\\Users\\User\\AppData\\Local\\Packages\\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\\LocalCache\\local-packages\\Python310\\site-packages\\transformers\\models\\deprecated\\trajectory_transformer\\convert_trajectory_transformer_original_pytorch_checkpoint_to_pytorch.py'
HINT: This error might have occurred since this system does not have Windows Long Path support enabled. You can find information on how to enable this at https://pip.pypa.io/warnings/enable-long-paths
-
安裝 leptonai 函式庫(Python)與 lep 命令列工具
pip install -U leptonai
leptonai 本身是用 Python 撰寫的。
-
直接從本機下載 Hugging Face 的 gpt2 模型
你可以用 lep photon run 搭配 --local 參數,在本機啟動任意一個 Hugging Face 上面的模型,執行成功後會在本機 Port 8080 啟動一個 API 伺服器,讓你直接可以呼叫本機部署的 gpt2 模型!
lep photon run --name 'gpt2' --model 'hf:gpt2' --local
目前並非所有 Hugging Face 上面的模型都可以透過 leptonai 來執行,而是要先透過一層 Photon 的封裝,才能順利跑起來。目前 Lepton AI 已經預先設計了市面上知名 LLM 模型的 Photons 物件,所以你才能這麼簡單的用一行命令跑起一個 LLM 模型,你可以參考 Prebuilt photons 查閱所有已支援的模型。
-
測試本機部署的 LLM 模型
以下是透過 Postman 測試 gpt2 模型的用法:
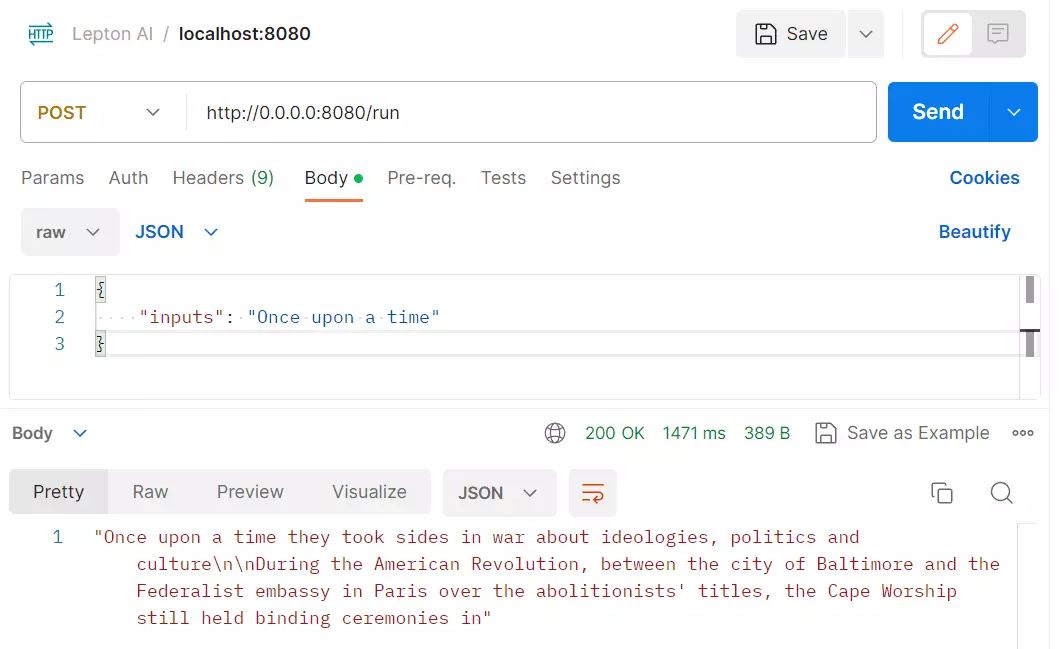
以下是透過 cURL 直接呼叫的命令範例:
curl -X 'POST' 'http://localhost:8080/run' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{"inputs": "Once upon a time"}'
在 Lepton AI 的雲端部署 LLM 模型
部署地端與部署雲端的步驟還蠻相似的,參數與命令都差不多,以下是部署 yentinglin/Taiwan-LLM-7B-v2.0.1-chat 模型的步驟說明:
-
安裝 leptonai 函式庫(Python)與 lep 命令列工具
請參閱本文前面的說明。
-
登入 Lepton AI 的 Dashboard 頁面並取得登入 Lepton Cloud 的命令
你可以用 Google 或 GitHub 帳號登入。
登入後可以從 Dashboard 頁籤找到 Getting Started 段落,點擊展開 Deploy in the cloud 即可找到登入 Lepton Cloud 的命令,請將這個命令複製到你的命令列工具中執行。
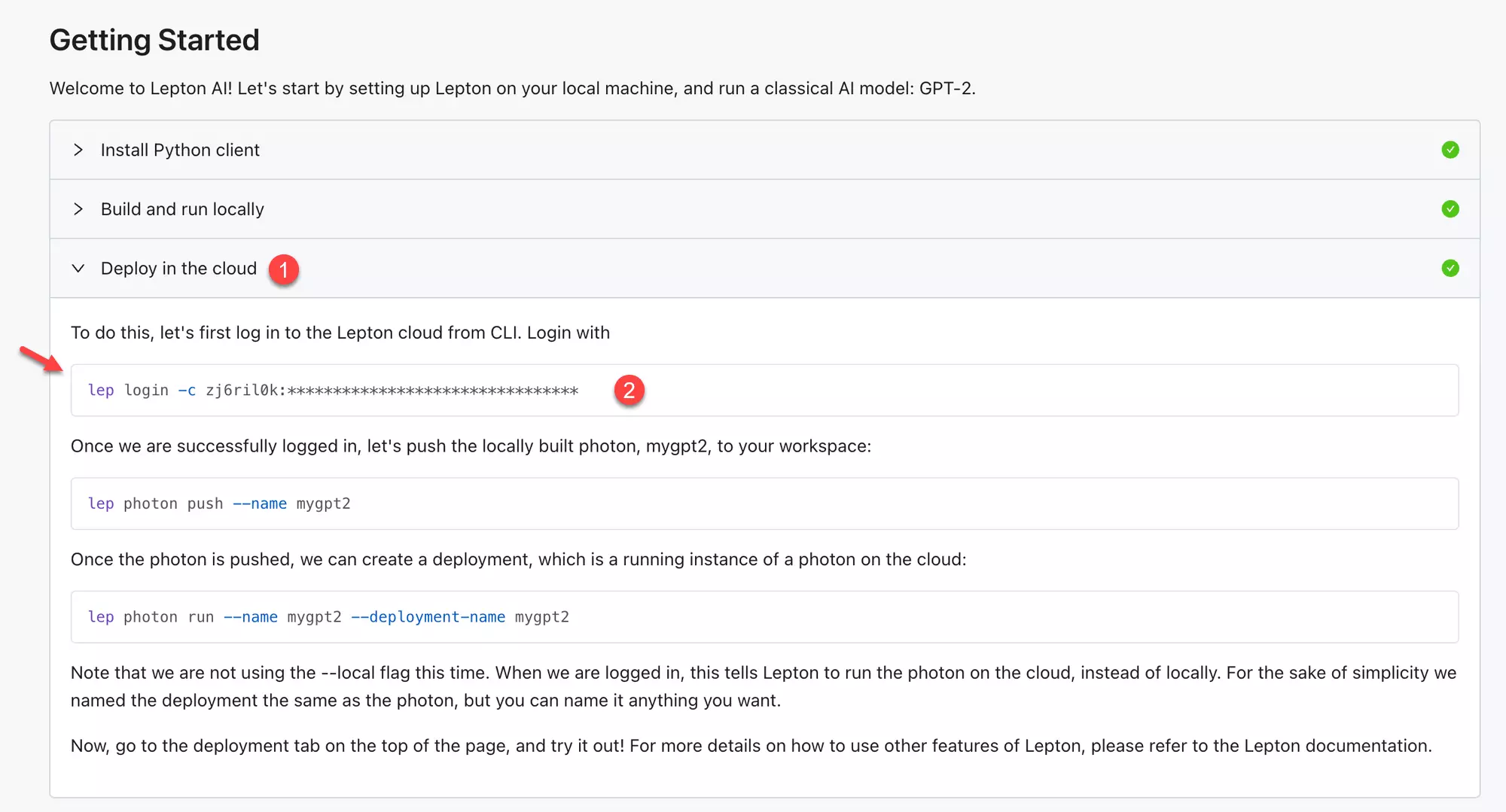
lep login -c oooooooo:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
其中的 oooooooo 是你的 workspace id
-
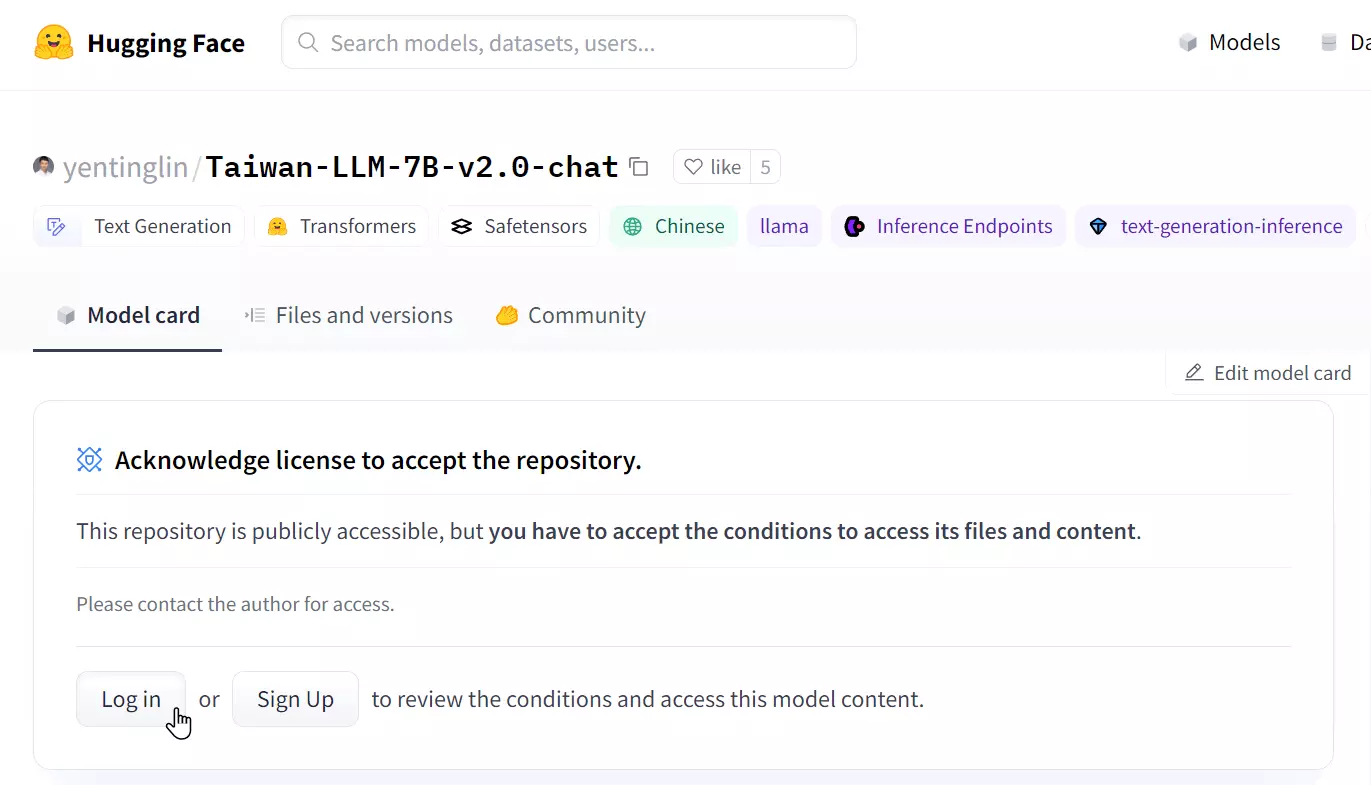
到 yentinglin/Taiwan-LLM-7B-v2.0.1-chat 申請使用授權
打開頁面後會看到 Acknowledge license to accept the repository. 的訊息,請點擊 Log in 或 Sign up 按鈕進行申請。
申請時不用輸入太多資料:
-
到 Hugging Face 的 Access Tokens 頁面建立一個 Hugging Face Hub Token
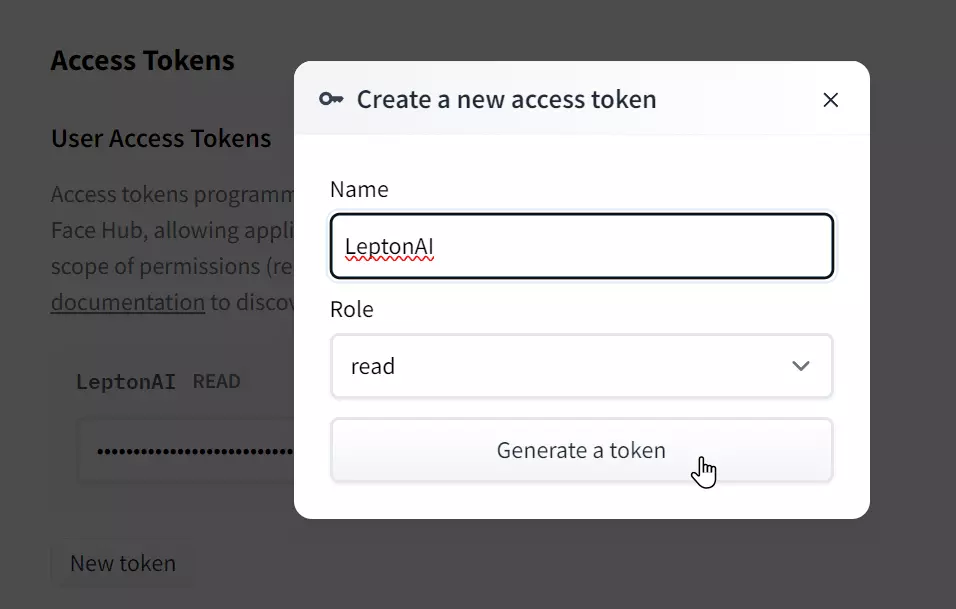
-
先利用 lep secret create 建立一個 HUGGING_FACE_HUB_TOKEN 密鑰 (Secret)
lep secret create -n HUGGING_FACE_HUB_TOKEN -v 'hf_xxxxxxxxxxxxxxxxxxxxxx'
其中 hf_xxxxxxxxxxxxxxxxxxxxxx 是你的 Hugging Face Hub Token
-
使用 lep photon run 命令建立一個可在 Lepton Cloud 執行的 Photon 物件
lep photon run --name 'taiwan-llm-7b' --model 'vllm:yentinglin/Taiwan-LLM-7B-v2.0.1-chat' --resource-shape 'gpu.a10' --secret 'HUGGING_FACE_HUB_TOKEN'
這裡的 --resource-shape 是指你要建立的雲端 VM 規格,由於 LLaMA 7B 模型所需的 GPU 記憶體比較大,至少要 24GB GRAM 才能跑得動,所以我要選用 gpu.a10 這個等級才能成功部署 yentinglin/Taiwan-LLM-7B-v2.0.1-chat 這個模型。目前 Lepton Cloud 支援的規格與計價標準可以參考 Resource Shapes 文件。
如果你執行的是 Hugging Face 公開的模型,那就不需要加上 --secret 參數。
-
等待部署完成
建立一台 gpu.a10 大約要等待 5 ~ 10 分鐘左右的部署時間,你可以用以下命令查看部署進度與狀態:
lep deployment status -n 'taiwan-llm-7b'
你也可以到 Lepton AI 的 Dashboard 頁面的 Deployments 頁籤查看部署狀態:
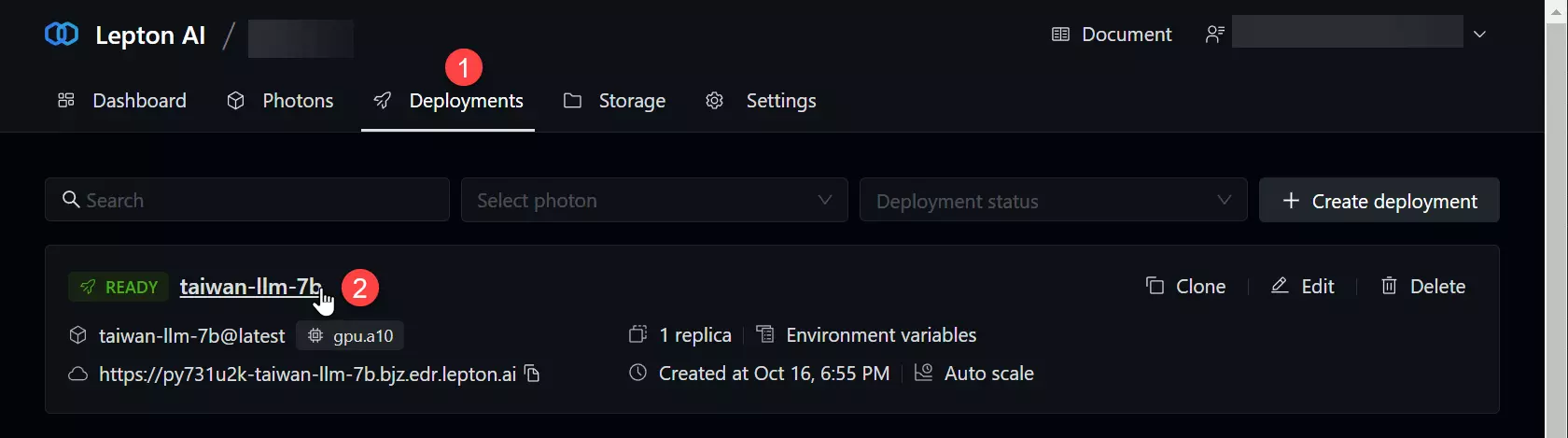
-
測試雲端部署的 LLM 模型
部署完成後,你會在 taiwan-llm-7b 的部署頁面看到 Demo, API, Metrics, Events, Replicas 等頁籤,可查看雲端部署的各種細部資訊。
其中 Demo 頁籤可以讓你很輕鬆的跟你剛部署的模型進行互動,直接呼叫該模型的 REST API 來測試。操作步驟如下圖示:
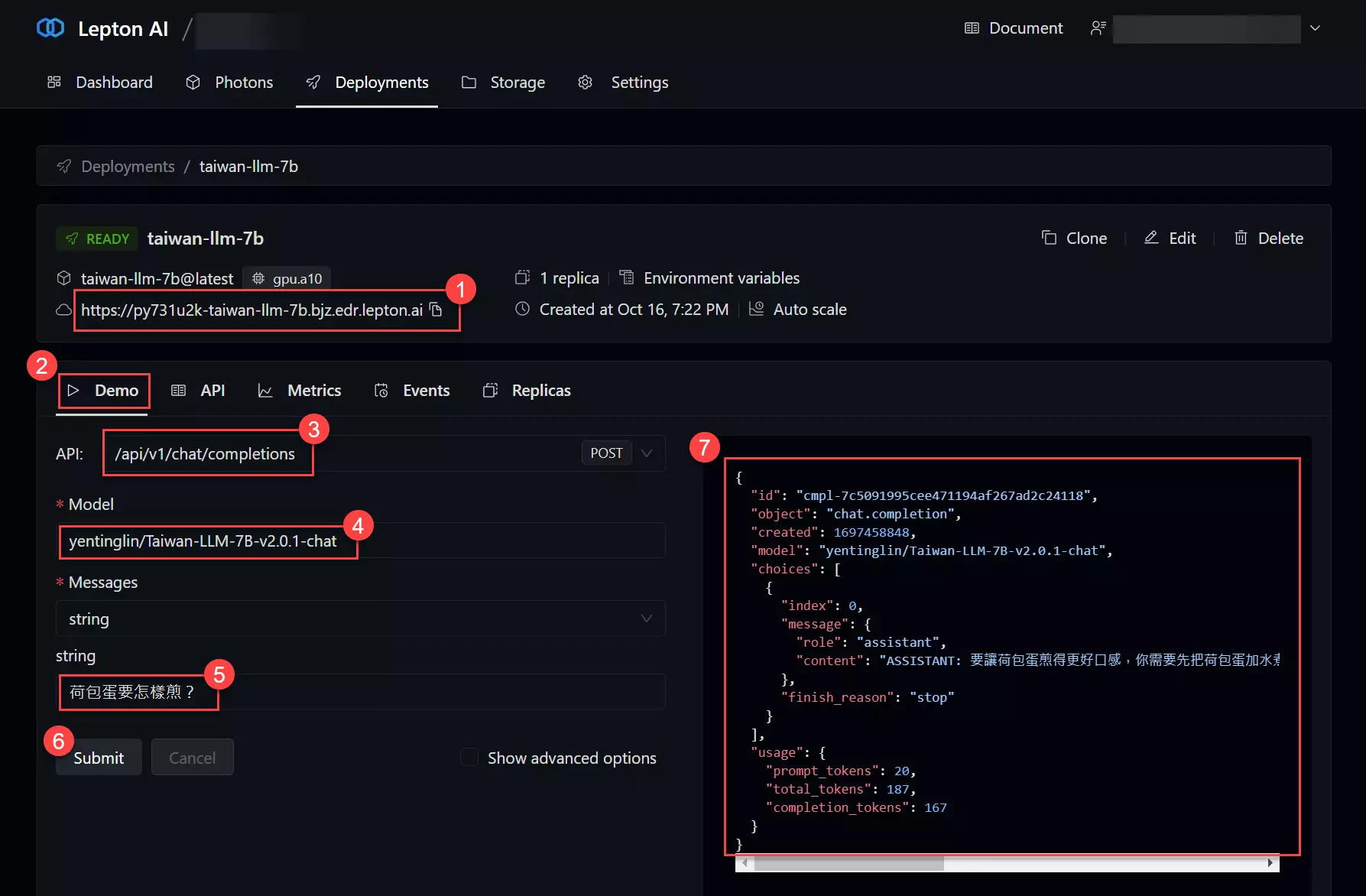
注意: Model 參數請輸入 yentinglin/Taiwan-LLM-7B-v2.0.1-chat。
然而 API 則會顯示該模型完整的 REST API 說明文件,你可以從這裡找到如何呼叫該模型的 REST API 服務。
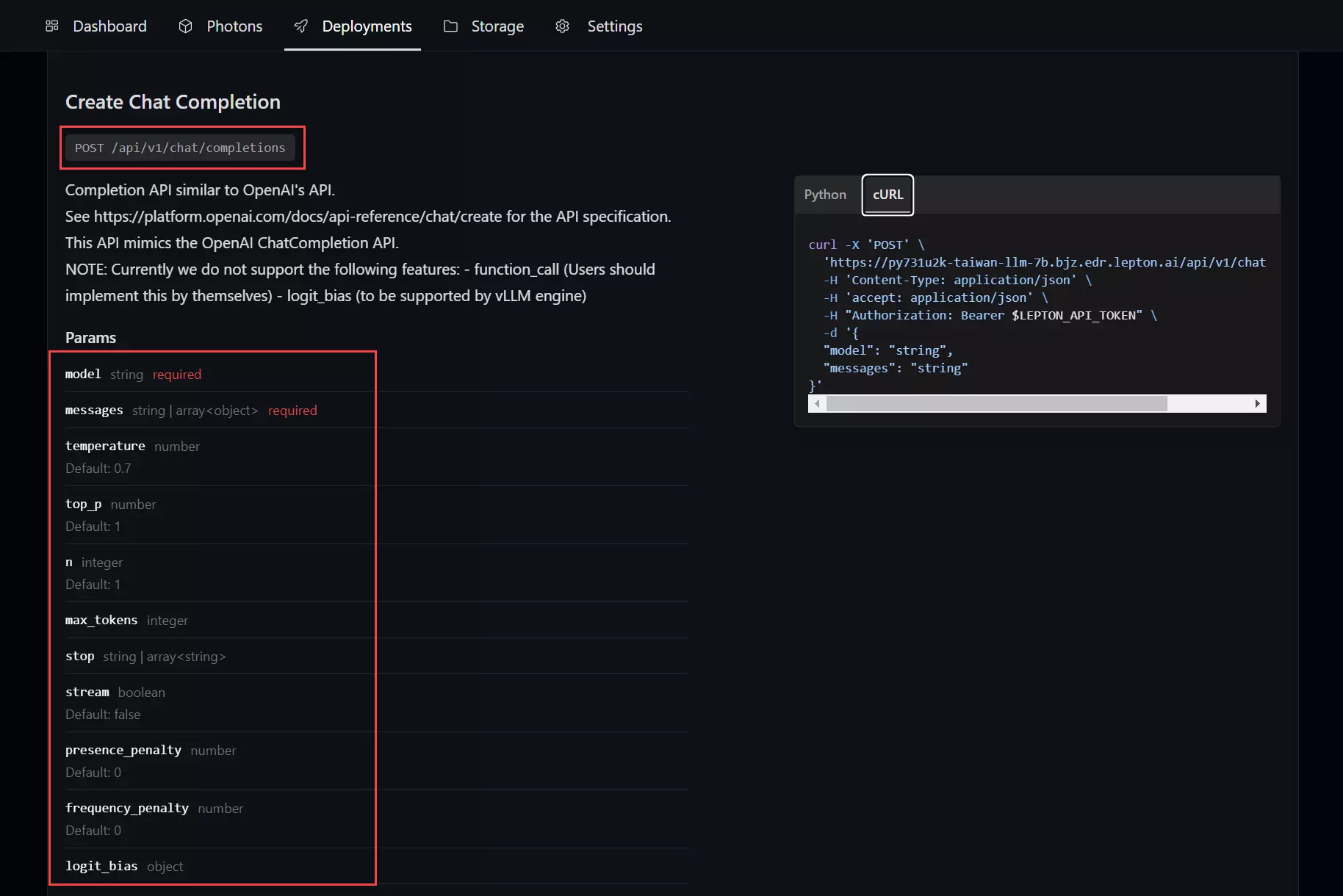
我依據 API 頁籤的說明,用 Postman 測試了一下,以下是測試的結果:
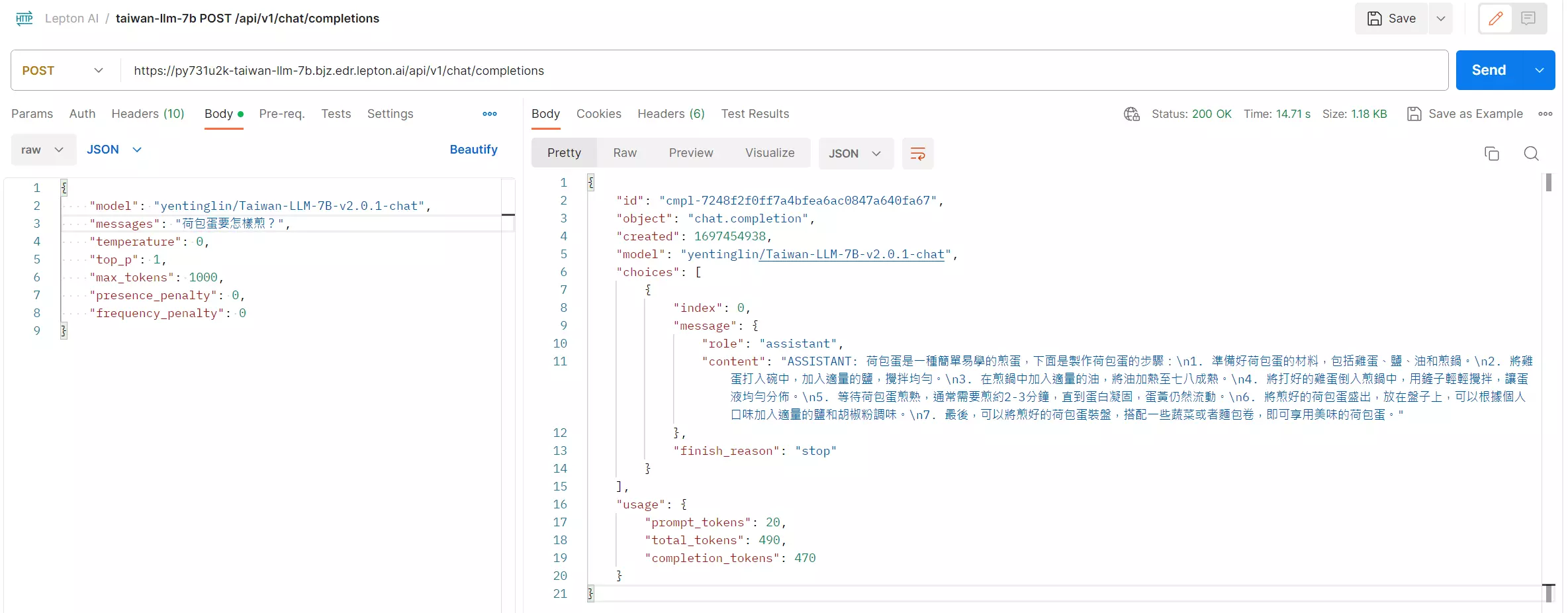
-
提高 LLM 模型部署規模
使用雲端的好處,就不是不用先買好一堆 A10 顯卡,如果想要大規模部署,直接調整 Replicas 數量即可。
例如你想要部署 5 台 A10 虛擬機,可以直接調整 Replicas 數量為 5:
lep deployment update -n 'taiwan-llm-7b' --min-replicas 5
說個秘密: 雲端部署的好處,就在於不用的時候隨時可以移除部署,以節省費用。只要 Replicas 數量更新為 0,也可以避免被收費喔!
-
移除雲端部署的 LLM 模型
基本上你只要輸入以下命令就可以列出目前所有 Deployments 物件:
lep deployment list
移除部署:
lep deployment remove -n 'taiwan-llm-7b'
當然,如果你下次想再重新部署的話,可以這樣執行:
lep photon run --name 'taiwan-llm-7b' --resource-shape 'gpu.a10' --secret 'HUGGING_FACE_HUB_TOKEN'
你可以保留 Photon 物件在 Lepton Cloud,儲存這個物件是不收費的,但如果你想要移除 Photon 物件的話,可以這樣執行:
lep photon remove -n 'taiwan-llm-7b'
總結
老實說,要在地端玩這些 Generative AI 模型是蠻花錢的,光是前期投資的 GPU 設備,少說都要花上好幾十萬,才能取得門票而已,一樣是一種有下限、無上限的遊戲。如果你是個獨立開發者,或是一個小型的團隊,想要玩玩這些 AI 模型,但又不想花太多錢,那麼像 Lepton AI 這種雲端部署服務 (又稱 LLMOps) 就是一個不錯的選擇,你可以先用雲端資源進行小規模的實驗,等到你的模型開發完成,或是想要擴大部署規模,到時再來考慮要不要買更高階的 GPU 設備來跑,這樣可以節省不少研發成本!
目前市面上有許多開源的模型,尤其是 Hugging Face 上面的模型有超過 30 萬個模型,部署這些模型都需要足夠的 GPU 資源才能跑起來,所以為什麼 LLMOps 會成為主流就是這樣,我們需要一個更好、更簡便的方式來部署這些 LLM 大語言模型。換句話說,如果你自己 fine-tune 了一個模型,想要給客戶試用,怎樣是最快的方法呢?當然是想找一個能夠快速部署的雲端服務,讓客戶可以快速試用你的模型,這樣才能讓客戶更快的接受你的產品,這就是 LLMOps 的價值所在。
目前 Lepton AI 正在發展一套名為 TUNA 的工具,可以提供你一套簡易的 API 就能 fine-tune 任何一套 LLM 模型,目前還在 Beta 階段,相信不久的將來就會正式釋出,到時候我們就可以更輕鬆的 fine-tune 自己的模型了!👍
最後,分享一個 Lepton AI 的 Playground 遊樂場,這邊部署了十多種開源的 AI 模型,目前有 Illusion Diffusion, Inpainting, Stable Diffusion XL, Whisper X, Llama2 7b, Llama2 13b, Llama2 70b, Code Llama 7b, Code Llama 13b, Code Llama 34b, Artistic Text, QR Code 等模型,你如果單純想實驗這些模型的效果,可以來這邊體驗一下,完全免費!
相關連結